Introducción
¡Bienvenidos! Si alguna vez te has preguntado cómo tu correo identifica el spam, cómo Netflix sabe qué serie recomendarte o cómo los coches autónomos aprenden a navegar, estás en el lugar correcto. Hoy vamos a sumergirnos en el corazón de la Inteligencia Artificial (IA): el Aprendizaje Automático o Machine Learning.
Estos conceptos no son solo “magia negra” tecnológica; son procesos de inducción del conocimiento basados en datos y algoritmos. Acompáñame en este recorrido didáctico para entender cómo las máquinas aprenden a generalizar comportamientos a partir de ejemplos.
1. ¿Qué es realmente el Aprendizaje Automático?
En esencia, el aprendizaje automático consiste en algoritmos que se ejecutan en ordenadores para aprender automáticamente basándose en datos proporcionados. A diferencia de la programación tradicional, donde damos instrucciones paso a paso, aquí creamos programas capaces de generalizar comportamientos a partir de ejemplos.
Podemos dividir este vasto campo en cuatro grandes áreas:
- Aprendizaje supervisado: Usamos ejemplos etiquetados (sabemos la respuesta de antemano).
- Aprendizaje no supervisado: No hay etiquetas; el algoritmo busca estructuras ocultas.
- Detección de anomalías: Identificación de casos inusuales o “outliers”.
- Aprendizaje por refuerzo: Aprender mediante la interacción con un entorno y recibir recompensas o castigos.
2. Aprendizaje Supervisado: El Arte de Predecir
En el aprendizaje supervisado, trabajamos con una “caja negra” donde introducimos variables de entrada  y obtenemos una respuesta
y obtenemos una respuesta  . El objetivo es encontrar una función
. El objetivo es encontrar una función  tal que:
tal que:

A. Problemas de Regresión
Aquí la variable respuesta es cuantitativa (numérica continua), como predecir el precio de una casa o los ingresos de una persona.
¿Cómo medimos si nuestro modelo es bueno? Usamos métricas de error como el Error Cuadrático Medio (MSE):

Otras métricas comunes incluyen el MAE (Error Absoluto Medio) y el RMSE (Raíz del Error Cuadrático Medio), que penaliza más los errores grandes.
B. Problemas de Clasificación
Aquí buscamos asignar una etiqueta o categoría. Puede ser binaria (spam o no spam) o multiclase (clasificar una imagen en perro, gato o ave).
Para evaluar estos modelos, la herramienta reina es la Matriz de Confusión. Esta tabla nos permite ver no solo cuántas veces acertó el modelo, sino en qué se equivocó. A partir de ella obtenemos:
- Accuracy (Exactitud): Proporción de predicciones correctas.
- Precisión: De lo que predijimos como positivo, ¿cuánto era realmente positivo?.
- Recall (Sensibilidad): De todo lo positivo que había, ¿cuánto logramos capturar?.
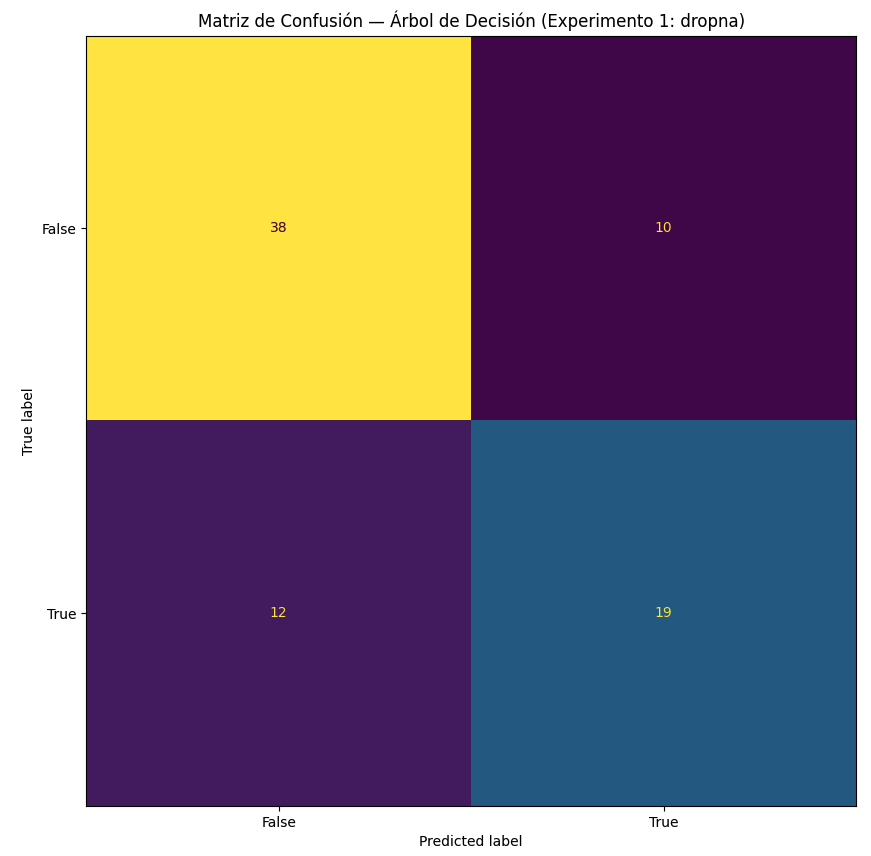
3. Algoritmos Protagonistas en la Clasificación
Naive Bayes: La simplicidad del azar
Este algoritmo se basa en el célebre Teorema de Bayes:

Se llama “Naive” (ingenuo) porque asume que todas las variables son independientes entre sí dado el valor de la clase, lo cual simplifica enormemente el cálculo computacional, aunque no siempre sea estrictamente cierto en la realidad. Es sumamente eficaz para clasificar texto.
Árboles de Decisión y Random Forests
Los Árboles de Decisión segmentan el espacio de las variables en regiones mediante reglas lógicas (ej. ¿Tiene más de 45 años?). Para decidir dónde hacer el “corte” perfecto, utilizan conceptos como la Entropía o el Índice Gini.
Sin embargo, un solo árbol puede sufrir de sobreajuste (overfitting). Aquí entra Random Forests, que es un “ensemble” o conjunto de muchos árboles. Utiliza una técnica llamada bagging y selección aleatoria de variables para reducir la varianza y mejorar la precisión.
Máquinas de Vector de Soporte (SVM)
Las SVM buscan el hiperplano óptimo que separa las clases con el mayor margen posible. Si los datos no se pueden separar con una línea recta, las SVM utilizan el Kernel Trick, transformando los datos a un espacio de mayor dimensión donde la separación sí sea posible.
4. Redes de Neuronas Artificiales: Imitando al Cerebro
Las redes neuronales modelan la relación entre señales de entrada y salida simulando el comportamiento cerebral mediante nodos interconectados. Son aproximadores universales, capaces de computar cualquier función matemática compleja.
Cada neurona procesa la información así:
- Recibe entradas ponderadas por pesos
 .
. - Las suma y aplica una función de activación (como la Sigmoide o ReLu).
- Propaga la señal a la siguiente capa.
El aprendizaje ocurre mediante el algoritmo de backpropagation, donde el error se propaga hacia atrás para ajustar los pesos y reducir fallos futuros usando el descenso del gradiente.
5. Aprendizaje No Supervisado: Buscando Patrones Ocultos
A veces no tenemos etiquetas. Aquí usamos el Clustering o agrupamiento.
Algoritmo K-medias (K-means)
Es el método más utilizado. El algoritmo:
- Elige
 puntos iniciales (centroides).
puntos iniciales (centroides). - Asigna cada dato al centroide más cercano (usualmente mediante distancia euclídea).
- Recalcula los centroides basándose en la media de los puntos asignados.
- Repite hasta que los grupos se estabilicen.

(Distancia Euclídea)
6. Detección de Anomalías y Aprendizaje por Refuerzo
Detección de Anomalías
Consiste en identificar observaciones significativamente diferentes al resto. Es vital en la detección de fraudes bancarios o fallos en motores de aviones. A menudo se modela la “normalidad” usando distribuciones Gaussianas; si la probabilidad de un nuevo dato  es menor a un umbral
es menor a un umbral  , se marca como anomalía.
, se marca como anomalía.
Aprendizaje por Refuerzo
Aquí un agente interactúa con un entorno. El agente percibe un estado, toma una acción y recibe una recompensa o castigo. El objetivo es aprender una política que maximice la recompensa a largo plazo. Un algoritmo clásico es el Q-Learning, donde se aprenden valores de “bondad” para cada par estado-acción.
7. El Toque Maestro: Optimización de Hiperparámetros
Incluso el mejor algoritmo necesita ajustes. Los hiperparámetros son parámetros que el desarrollador debe establecer antes del entrenamiento (ej. el número de árboles en un bosque o la tasa de aprendizaje en una red neuronal).
Existen dos estrategias principales para encontrar los valores óptimos:
- Grid Search (Búsqueda en Rejilla): Probamos todas las combinaciones posibles de una lista manual. Es exhaustivo pero lento.
- Random Search (Búsqueda Aleatoria): Selecciona combinaciones al azar. Se ha demostrado que es más eficiente en espacios de alta dimensión, ya que no pierde tiempo en parámetros que afectan poco al resultado.
8. Consideraciones Finales: Entrenamiento, Test y Validación
Para que todo esto funcione de forma rigurosa, nunca debemos evaluar nuestro modelo con los mismos datos que usamos para entrenarlo. Lo estándar es dividir los datos:
- Conjunto de Entrenamiento (80%): Para que el modelo aprenda.
- Conjunto de Test (20%): Para evaluar su capacidad real de generalizar ante datos nuevos.
Una técnica superior es la Validación Cruzada (k-fold), donde dividimos los datos en  partes y entrenamos/probamos el modelo veces, rotando los datos, para obtener una métrica de rendimiento mucho más robusta.
partes y entrenamos/probamos el modelo veces, rotando los datos, para obtener una métrica de rendimiento mucho más robusta.
Conclusión
El Aprendizaje Automático no es solo una colección de algoritmos; es una forma de resolver problemas complejos donde la estadística clásica se queda corta. Desde la elegancia probabilística de Naive Bayes hasta la potencia bruta de las Redes Neuronales y los Random Forests, estas herramientas han estado transformando la industria por décadas sin que te dieras cuenta, lo hacen ahora mas que nunca y lo seguirán haciendo puesto que han demostrado ser muy eficientes.
Entender estos fundamentos es el primer paso para no solo ser consumidores de tecnología, sino creadores informados. La próxima vez que tu asistente de voz entienda tu comando, recuerda: hay una función trabajando duro detrás de escena para entender tu mundo.
Referencias bibliográficas principales:
- James, G. et al. (2013/2017). An Introduction to Statistical Learning..
- Brett, L. (2013). Machine Learning with R..
- Sutton, R. S. & Barto, A. (1998). Reinforcement Learning..